Средство отслеживания масок преобразует маску в соответствии с траекторией перемещения одного или нескольких объектов в фильме. Выбранный для отслеживания объект на протяжении всего фильма должен сохранять одну и ту же форму, однако может менять расположение, масштаб и/или перспективу, поскольку такие изменения не препятствуют отслеживанию.
При выделении маски панель «Отслеживание» переключается в режим отслеживания маски и отображает следующие элементы управления:
- Выполните отслеживание в направлении вперед или назад применительно к одному кадру во времени или до конца слоя
- Метод, с помощью которого можно изменить расположение, масштаб, поворот, наклон и перспективу маски
Выберите маску, а затем пункты Анимация > Отслеживать маску . Вместо этого также можно, удерживая нажатой клавишу CONTEXT, щелкнуть маску и выбрать Отслеживать маску в контекстном меню, чтобы отобразить панель «Отслеживание».
Эффект Увеличение с сохранением уровня детализации предоставляет возможность значительно увеличить изображение, сохранив при этом его мелкие элементы, а также резкость линий и кривых. Например, можно масштабировать кадры из формата SD в формат HD или из формата HD в формат кадра для цифрового кино.
Дополнительные сведения см. в разделе Эффект «Увеличение с сохранением уровня детализации» .
Средства просмотра содержимого HiDPI для экранов Retina на компьютерах Mac
After Effects отображает содержимое на экранах Retina компьютеров Mac таким образом, чтобы каждый пиксель содержимого в средстве просмотра отображался в качестве отдельного пикселя на экране.
Это влияет на содержимое следующих элементов:
- Панель «Видеоряд»
- Панель «Слой»
- Панель «Композиция», в том числе видеосодержимое и некоторые элементы интерфейса в области содержимого
Эта особенность не влияет на курсоры, кнопки и другие панели пользовательского интерфейса After Effects.
Обновленные функции Cineware
В диалоговом окне Параметры
в разделе эффектов Cineware появились два новых параметра. С их помощью можно настроить экземпляр Cinema 4D, который будет использоваться в сочетании с After Effects.
Путь рендеринга Cinema 4D:
выбор версии Cinema 4D (R14 или R15), которая будет применяться для рендеринга при работе в After Effects.
Путь к исполнимому файлу Cinema 4D
: выбор версии Cinema 4D, которая будет использоваться при открытии файла .c4d
в After Effects, например с помощью команды Редактировать оригинал
.
Дополнительные сведения см. в разделе Обновления Cinema 4D .
Новая библиотека OptiX для 3D-рендеринга с трассировкой лучей
After Effects CC теперь использует новую библиотеку OptiX 3.0. В предыдущих версиях After Effects применялась библиотека OptiX 2.0.
Основные преимущества новой библиотеки OptiX перед старой библиотекой Optix 2.0:
- Устранены причины сбоя в Mac OS X v10.9 (Mavericks)
- Более высокая производительность, в том числе в среде с несколькими ГП
Обход белого списка для ускорения ГП в случае 3D-рендеринга с трассировкой лучей
В диалоговом окне «Данные ГП» представлено меню с параметрами трассировки лучей, в котором пользователь может выбрать ГП или ЦП.
В предыдущих версиях After Effects при отсутствии установленного оборудования в списке протестированных и поддерживаемых ГП соответствующий пункт в меню ГБ блокировался (выделялся серым), а под меню отображалось сообщением «GPU недоступно - несовместимое устройство или драйвер дисплея».
Теперь пользователям доступен новый параметр для настройки ГП, представленный в меню Правка > Установки > Предпросмотр > Данные ГП : «Использовать непроверенный, неподдерживаемый ГП для ускорения 3D-рендеринга с трассировкой лучей CUDA».
Если этот флажок установлен, After Effects использует ускоренный графический 3D-рендеринг с трассировкой лучей с применением любого ГП, соответствующего минимальным требованиям.
Список новых карт в белом списке CUDA для OptiX
В белый список CUDA для OptiX (для графического ускорения 3D-рендеринга с трассировкой лучей) были добавлены следующие карты:
- GTX 675MX (Windows и Mac OS)
- GTX 680MX (Windows и Mac OS)
- GTX 590 (Windows)
- GT 650M (добавлена в список карт для Windows; уже представлена в списке Mac OS)
- GTX 760 (Windows)
- GTX 770 (Windows)
- GTX 780 (Windows)
- GTX TITAN (Windows)
- Quadro K6000 (Windows)
- Quadro K4000 (Windows)
- Quadro K2000 (Windows)
- Quadro K5000M (Windows)
- Quadro K4000M (Windows)
- Quadro K3000M (Windows)
- Quadro K5100M (Windows)
- Quadro K4100M (Windows)
- Quadro K3100M (Windows)
- Quadro K2100M (Windows)
Повышена производительность на этапе анализа для функции 3D Camera Tracker и стабилизатора деформации
Значительно ускорен фоновый процесс анализа видеоряда для функции 3D Camera Tracker и стабилизатора деформации. В зависимости от сведений о видеоряде и других факторов полученные показатели увеличения скорости обработки на этапе анализа (отслеживания) составляют от 60 % до 300 %.
Улучшенные и измененные свойства
Показать свойства с ключевыми кадрами
Изменились команды для отображения измененных свойств в панели Таймлайн ; теперь в меню Анимация представлены три команды для отображения свойств:
- Показать свойства с ключевыми кадрами (клавиша U) - отображение любого свойства, с которым связан ключевой кадр. Если со свойством одновременно связаны и ключевые кадры, и выражения, данное свойство отображается, но не отображается связанное с ним выражение.
- Показать свойства с анимацией - отображению любого свойства, с которым связан ключевой кадр или выражение.
- Показать все измененные свойства (комбинация клавиш: UU) - отображение ключевых кадров, выражений или всех измененных свойств (включая ключевые кадры и выражения), которые не анимированы.
Создание ссылок на свойства
- Выберите любое свойство или набор свойств.
- Выберите Правка > Копировать со ссылками свойства.
- Вставьте свойства в любой слой любой композиции.
Вставленные свойства теперь сохраняют связь со слоем, из которого они были скопированы. Благодаря этому любое изменение, внесенное в исходное свойство, отражается на всех экземплярах данного свойства, добавленных посредством ссылки.
Чтобы создать дубликаты, которые будут отражать изменения, внесенные в оригинал, можно скопировать и вставить весь слой со ссылками на свойства. Также можно создать ссылки на группы свойств, представленные в том или ином слое. Например, чтобы создать ссылки на все свойства преобразования, не выбирая их по отдельности, скопируйте группу преобразования и вставьте ее в другой слой.
Новые свойства в меню «Язык выражения»
Исправленные звуковые волны
В After Effects звуковые волны представлены как «исправленные» звуковые волны. Это означает, что амплитуда звука отображается только в одном направлении по горизонтальной оси на логарифмической шкале. Данный метод отображения упрощает расчет восприятия громкости звука.
Чтобы переключиться на старый метод отображения звуковых волн, снимите флажок Исправленные звуковые волны
в меню панели «Таймлайн».
Изменения метода привязки слоев 2D и 3D
Рядом с флажком «Привязка» в панели «Инструменты» добавлены два новых параметра:
Привязка вдоль краев расширена за границы слоя: включение привязки к линиям за границами слоя. Например, привязка вдоль линии, заданной расширением края слоя в 3D-пространстве. Эта функция значительно упрощает выравнивание слоев в 3D-пространстве.
Привязка к функциям внутри свернутых композиций и текстовых слоев : вращение внутренних каркасов для слоев, которые находятся внутри композиций, со свернутыми трансформациями, а также для отдельных символов в посимвольных текстовых 3D-слоях. С помощью этой функции можно, например, привязать опорную точку одного слоя к другому слою в композиции.
Включение предпросмотра видео для внешних устройств (Mac OS)
Чтобы активировать предпросмотр видео на внешних устройствах в Mac OS, выберите новый параметр Включить предпросмотр видео QuickTime в категории установок Предросмотр видео . При установке данного флажка After Effects запросит у QuickTime список внешних устройств для предпросмотра видео.
Внимание! Активация этого параметра может привести к отказу Adobe QT32 Server, что в свою очередь приведет к сбою After Effects.
Более ранние версии After Effects автоматически запрашивают в QuickTime список внешних устройств для предпросмотра видео.
Изменения и улучшения функций для работы со слоями
Центральная опорная точка
Опорную точку, которая станет центром содержимого слоя, можно задать следующими способами:
- Слой > Трансформировать > Расположить опорную точку в содержимом слоя по центру
- В ОС Windows используйте комбинацию клавиш Ctrl+Alt+Home , в Mac OS - комбинацию клавиш Command+Option+Home .
- Также можно использовать комбинацию Ctrl+двойной щелчок (Windows) или Command+двойной щелчок (Mac OS) для активации инструмента Панорамирование назад (опорная точка) .
Сведения об опорных точках см. в разделе Свойства опорных точек .
Создание нового слоя
Настройка длительности предварительной композиции
В диалоговом окне Предварительная композиция появился новый параметр: Настройте продолжительность композиции к временному диапазону выделенных слоев .
Выберите этот параметр, чтобы создать новую композицию с такой же длительностью, как у выбранных слоев.
В предыдущих версиях After Effects длительность новой композиции совпадает с длительностью исходной вне зависимости от длительности слоев, вошедших в предварительную композицию.
Бикубическая выборка эффекта «Преобразовать»
У эффекта Преобразовать появился новый параметр Выборка , для которого можно выбрать значение Билинейная или Бикубическая .
Включить ведение журнала
Выберите Справка > Включить ведение журнала , чтобы записать сведения о сеансе. Созданные журналы будут отправлены в набор текстовых файлов. Чтобы начать процесс ведения журнала, перезапустите приложение. Чтобы просмотреть файлы журнала, выберите Справка > Показать файл журнала .
Примечание. Ведение журнала несколько снижает производительность, поэтому функция ведения журнала, включенная с помощью этого параметра, будет выключена через 24 часа.
Автоматическое открытие папок панели «Проект» при перетаскивании
.Привет всем! Сегодня очень интересная статья о тонкой настройке видеокарты для высокой производительности в компьютерных играх. Согласитесь друзья, что после установки драйвера видеокарты вы один раз открыли «Панель управления Nvidia» и увидев там незнакомые слова: DSR, шейдеры, CUDA, синхроимпульс, SSAA, FXAA и так далее, решили туда больше не лазить. Но тем не менее, разобраться во всём этом можно и даже нужно, ведь от данных настроек напрямую зависит производительность . Существует ошибочное мнение, что всё в этой мудрёной панели настроено правильно по умолчанию, к сожалению это далеко не так и опыты показывают, правильная настройка вознаграждается весомым увеличением кадровой частоты. Так что приготовьтесь, будем разбираться в потоковой оптимизации, анизотропной фильтрации и тройной буферизации. В итоге вы не пожалеете и вас будет ждать награда в виде увеличения FPS в играх.
Настройка видеокарты Nvidia для игр
Темпы развития игрового производства с каждым днем набирают все больше и больше оборотов, впрочем, как и курс основной денежной единицы в России, а поэтому актуальность оптимизации работы железа, софта и операционной системы резко повысилась. Держать своего стального жеребца в тонусе за счет постоянных финансовых вливаний не всегда удается, поэтому мы с вами сегодня и поговорим о повышении быстродействия видеокарты за счет ее детальной настройки. В своих статьях я неоднократно писал о важности установки видеодрайвера, поэтому , думаю, можно пропустить. Я уверен, все вы прекрасно знаете, как это делать, и у всех вас он давно уже установлен.
Итак, для того, чтобы попасть в меню управления видеодрайвером, кликайте правой кнопкой мыши по любому месту на рабочем столе и выбирайте в открывшемся меню «Панель управления Nvidia».
После чего, в открывшемся окне переходите во вкладку «Управление параметрами 3D».
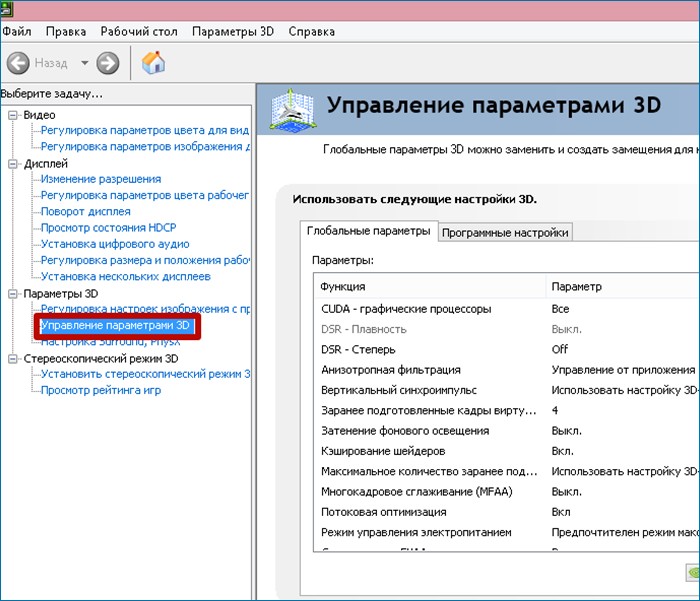
Здесь мы с вами и будем настраивать различные параметры, влияющие на отображение 3D картинки в играх. Не трудно понять, что для получения максимальной производительности видеокарты придется сильно порезать изображение в плане качества, так что будьте к этому готовы.
Итак, первый пункт «CUDA – графические процессоры ». Здесь представлен список видеопроцессоров, один из которых вы можете выбрать, и он будет использоваться приложениями CUDA. CUDA (Compute Unified Device Architecture) – это архитектура параллельных вычислений использующаяся всеми современными графическими процессорами для увеличения вычислительной производительности.

Следующий пункт «DSR - Плавность » мы пропускаем, потому что он является частью настройки пункта "DSR - Степень”, а его в свою очередь нужно отключать и сейчас я объясню почему.

DSR (Dynamic Super Resolution) – технология позволяющая рассчитывать картинку в играх в более высоком разрешении, а затем масштабирующая полученный результат до разрешения вашего монитора. Для того чтобы вы поняли для чего эта технология вообще была придумана и почему она не нужна нам для получения максимальной производительности, я попробую привести пример. Наверняка вы часто замечали в играх, что мелкие детали, такие как трава и листва очень часто мерцают или рябят при движении. Связано это с тем, что, чем меньше разрешение, тем меньше число точек выборки для отображения мелких деталей. Технология DSR позволяет это исправить за счет увеличения числа точек (чем больше разрешение, тем больше число точек выборки). Надеюсь, так будет понятно. В условиях максимальной производительности эта технология нам не интересна так, как затрачивает довольно много системных ресурсов. Ну а с отключенной технологией DSR, настройка плавности, о которой я писал чуть выше, становится невозможна. В общем, отключаем и идем дальше.
Далее идет анизотропная фильтрация . Анизотропная фильтрация – алгоритм компьютерной графики, созданный для улучшения качества текстур, находящихся под наклоном относительно камеры. То есть при использовании данной технологии текстуры в играх становятся более четкие. Если сравнивать антизотропную фильтрацию со своими предшественниками, а именно с билинейной и трилинейной фильтрациями, то анизотропная является самой прожорливой с точки зрения потребления памяти видеокарты. Данный пункт имеется только одну настройку – выбор коэффициента фильтрации. Не трудно догадаться, что данную функцию необходимо отключать.

Следующий пункт – вертикальный синхроимпульс . Это синхронизация изображения с частотой развертки монитора. Если включить данный параметр, то можно добиться максимально плавного геймплея (убираются разрывы изображения при резких поворотах камеры), однако зачастую возникают просадки кадров ниже частоты развертки монитора. Для получения максимального количества кадров в секунду данный параметр лучше отключить.

Заранее подготовленные кадры виртуальной реальности . Функция для очков виртуальной реальности нам не интересна, так как VR еще далека до повседневного использования обычных геймеров. Оставляем по умолчанию – использовать настройку 3D приложения.

Затенение фонового освещения . Делает сцены более реалистичными за счет смягчения интенсивности окружающего освещения поверхностей, которые затенены находящимися рядом объектами. Функция работает не во всех играх и очень требовательна к ресурсам. Поэтому сносим ее к цифровой матери.

Кэширование шейдеров . При включении данной функции центральный процессор сохраняет скомпилированные для графического процессора шейдеры на диск. Если этот шейдер понадобится еще раз, то GPU возьмет его прямо с диска, не заставляя CPU проводить повторную компиляцию данного шейдера. Не трудно догадаться, что если отключить этот параметр, то производительность упадет.

Максимальное количество заранее подготовленных кадров . Количество кадров, которое может подготовить ЦП перед их обработкой графическим процессором. Чем выше значение, тем лучше.
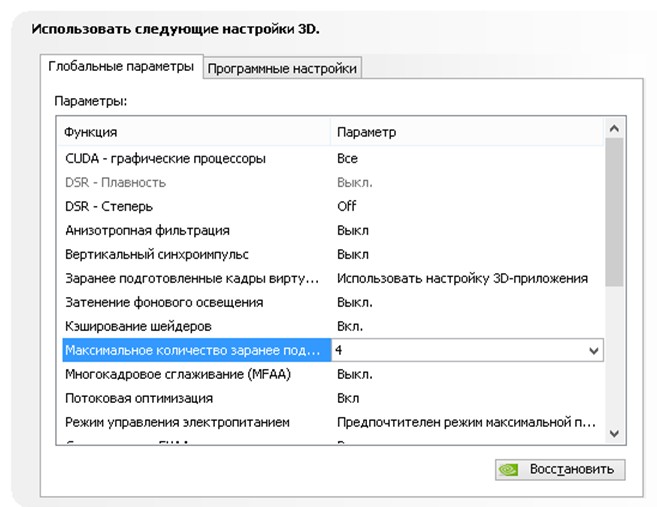
Многокадровое сглаживание (MFAA) . Одна из технологий сглаживания используемая для устранения "зубчатости” на краях изображений. Любая технология сглаживания (SSAA, FXAA) очень требовательна к графическому процессору (вопрос лишь в степени прожорливости). Выключаем.

Потоковая оптимизация . Благодаря включению этой функции приложение может задействовать сразу несколько ЦП. В случае, если старое приложение работает некорректно попробуй поставить режим "Авто” или же вовсе отключить эту функцию.

Режим управления электропитанием . Возможно два варианта – адаптивный режим и режим максимальной производительности. Во время адаптивного режима энергопотребление зависит напрямую от степени загрузки ГП. Этот режим в основном нужен для снижения энергопотребления. Во время режима максимальной производительности, как не трудно догадаться, поддерживается максимально возможный уровень производительности и энергопотребления независимо от степени загрузки ГП. Ставим второй.

Сглаживание – FXAA, Сглаживание – гамма-коррекция, Сглаживание – параметры, Сглаживание – прозрачность, Сглаживание - режим . Про сглаживание я уже писал чуть выше. Выключаем всё.

Тройная буферизация . Разновидность двойной буферизации; метод вывода изображения, позволяющий избежать или уменьшить количество артефактов (искажение изображения). Если говорить простыми словами, то увеличивает производительность. НО! Работает эта штука только в паре с вертикальной синхронизацией, которую, как вы помните, мы до этого отключили. Поэтому этот параметр тоже отключаем, он для нас бесполезен.
Переводим... Перевести Китайский (упрощенное письмо) Китайский (традиционное письмо) Английский Французский Немецкий Итальянский Португальский Русский Испанский Турецкий
К сожалению, мы не можем перевести эту информацию прямо сейчас - пожалуйста, повторите попытку позже.
Введение
В этом примере демонстрируется создание текстуры в OpenGL* 4.3, подчиненная область которой обновляется ядром С OpenCL™, выполняющимся на ГП Intel® Processor Graphics под управлением Microsoft Windows*. Одним из назначений такой технологии могут быть приложения компьютерного зрения в реальном времени, где необходимо запускать детектор определенных элементов изображения в OpenCL, но в реальном времени выводить готовое изображение с четко отмеченными детекторами на экран. В этом случае нужен доступ ко всем возможностям языка С ядра OpenCL, а также возможности рендеринга API OpenGL для совместимости с существующим конвейером рендеринга. Еще один пример использования такой технологии: если динамически создаваемые в OpenCL процедурные текстуры используются для рендеринга трехмерных объектов на сцене. И наконец, представьте себе постобработку изображения в OpenCL после рендеринга сцены с помощью 3D конвейера. Это может быть полезно для преобразования цветов, изменения разрешения или выполнения сжатия в определенных сценариях.
В этом примере показано обновление в OpenCL текстуры, созданной в OpenGL. Такие же рекомендации применяются для обновления объекта вертексного буфера или внеэкранного кадрового буфера, который может использоваться в автономном конвейере обработки изображений.
Расширение общего доступа к поверхностям определяется в спецификации расширений OpenCL строкой cl _ khr _ gl _ sharing . Мы также используем расширение cl _ khr _ gl _ event , которое поддерживается ГП Intel.
Мотивация
Назначение этого учебного руководства в том, чтобы ознакомить читателей с возможностью создания поверхностей, общих для OpenCL и OpenGL. Также вы сможете лучше понять работу API, соображения производительности различных путей создания текстур в API OpenGL, в частности на ГП Intel, а также разницу между таким подходом и использованием дискретных ГП.
Основной принцип
Для создания текстур OpenGL и доступа к ним как к изображениям OpenCL с наивысшей производительностью ГП Intel не следует создавать объект пиксельного буфера (РВО) OpenGL. Объекты PBO не обладают преимуществами производительности на ГП Intel. Кроме того, они создают по крайней мере одну дополнительную линейную копию данных, которые затем копируются в формат текстур, используемый в ГП для рендеринга. Во-вторых, вместо использования glFinish () для синхронизации между OpenCL и OpenGL мы можем использовать механизм неявной синхронизации, поскольку ГП Intel поддерживает расширение cl _ khr _ gl _ event .
ГП Intel® с общей физической памятью
ГП Intel® и ЦП вместе используют общую память. Их взаимоотношение показано на рисунке 1. Существует несколько архитектурных механизмов (не показанных на этом рисунке), расширяющих возможности подсистемы памяти. Например, для повышения производительности подсистемы памяти применяются иерархии кэша, сэмплеры, элементарные операции, очереди чтения и записи.
Рисунок 1. Взаимоотношения между ЦП, ГП Intel ® и основной памятью. Обратите внимание, что ЦП и ГП используют общий пул памяти (в отличие от дискретных ГП с собственной выделенной памятью, управление которой осуществляет драйвер)
Почему не следует использовать объекты пиксельного буфера (РВО) с ГП Intel
«Основное преимущество использования объекта буфера для промежуточного хранения данных текстуры состоит в том, что передача из объекта буфера в текстуру не должна обязательно происходить немедленно, если она происходит до момента, когда данные требуются шейдеру. Это позволяет осуществлять передачу параллельно с выполнением приложения. Если же данные находятся в памяти приложения, то семантика glTexSubImage 2 D () требует, чтобы перед возвратом функции была создана копия данных , благодаря чему исключается параллельная передача. Преимущество такого подхода состоит в том, что приложение может свободно изменять данные, переданные в функцию, сразу после возврата функции».
Обратите внимание, что смысл этого вызова API заключается в общем доступе между памятью приложения (т. е. памятью ЦП) и ГП, а не в общем доступе между двумя API, каждый из которых выполняет свой поток команд на одном и том же устройстве и одной и той же физической памяти, как показано на рисунке 1.
Использование объектов PBO на самом деле приводит к снижению производительности на устройствах, где используется общая физическая память. Во-первых, объект РВО - это дополнительная промежуточная область, что означает увеличение объема памяти, потребляемого приложением. Во-вторых, данные в РВО хранятся в линейном виде, а если данные требуются в сегментированном виде, как, например, в текстурах OpenGL или в изображениях OpenCL, то приходится преобразовывать данные в нужный формат. И наконец, копирование между двумя API занимает определенное время, что также отрицательно сказывается на производительности приложения.
В случае общего доступа с дискретным ГП использование объектов РВО вполне целесообразно: можно запустить передачу DMA, работающую асинхронно по отношению к ЦП. Без РВО семантика OpenGL требует синхронной записи и дожидается возвращения результата, что также снижает производительность. В нашем случае нет передачи данных из ЦП в подсистему памяти ГП.
В каких случаях можно использовать РВО при общем доступе к поверхностям?
Существуют сценарии, когда имеет смысл применять объекты РВО. Например, если не существует подходящего формата поверхностей, совместимого с OpenGL и OpenCL согласно таблице 9.4 в спецификации расширений OpenCL. В этом случае можно создать РВО и предоставить к нему общий доступ для API, связанных с общим доступом к буферу. Тем не менее старайтесь избегать таких сценариев, чтобы не допустить снижения производительности, о котором было сказано выше. Если это необходимо, см. пример Максима Шевцова, ссылка на который приводится в разделе справочных материалов.
Синхронизация между OpenCL™ и OpenGL*
Во время выполнения важно добиться наивысшей производительности OpenCL и OpenGL. В спецификации сказано следующее:
«Перед вызовом объектов clEnqueueAcquireGLObjects приложение должно убедиться в завершении всех отложенных операций GL , располагающих доступом к объектам, указанным в mem _ objects . Чтобы сделать это с сохранением переносимости, можно выполнить и дождаться завершения команды glFinish для всех контекстов GL с отложенными ссылками на эти объекты. В разных реализациях могут быть доступны более эффективные методы синхронизации. Например, на некоторых платформах может оказаться достаточно вызвать glFlush , или же синхронизация может быть неявной внутри потока, или могут быть поддерживаемые данным поставщиком расширения, позволяющие разграничивать поток команд GL и дожидаться завершения каждой части в очереди команд CL . Обратите внимание, что в данный момент единственным методом синхронизации, поддерживающим перенос между различными реализациями OpenGL , является glFinish ».
Для наибольшей переносимости, согласно спецификации, нужно вызывать glFinish () , но это блокирующий вызов! На ГП Intel будет эффективнее использовать неявную синхронизацию или объекты синхронизации между OpenCL и OpenGL с расширением cl _ khr _ gl _ events . Подробнее это будет описано ниже. Использование неявной синхронизации не является обязательным. В образце кода содержатся закомментированные фрагменты, которые можно задействовать, если нужно использовать неявную синхронизацию.
Обзор общего доступа к поверхностям для OpenCL и OpenGL
Сначала опишем этапы, необходимые для поддержки общего доступа к поверхностям при инициализации, выполнении и завершении работы. Затем более подробно опишем API и синтаксис языка. И наконец, мы расскажем, как можно развить эти идеи, чтобы охватить другие форматы текстур, выходящие за рамки данного примера. Мы используем общедоступную библиотеку freeglut для управления окнами, а также библиотеку glew . Использование этих библиотек является стандартной практикой в образцах приложений OpenGL, поэтому мы не будем описывать их подробнее.
Инициализация
- OpenCL:
- Создайте контекст, передающий соответствующие параметры устройства.
- Создайте очередь на устройстве и контекст, поддерживающий обмен данными между OpenGL и OpenCL.
- OpenGL: Создайте текстуру OpenGL, доступ к которой нужно предоставить для OpenCL.
- OpenCL: С помощью дескриптора OpenGL, созданного на шаге 2, создайте общую поверхность посредством расширения OpenCL.
Шаги 1 и 2 можно поменять местами. Шаг 3 должен следовать за шагами 1 и 2.
Запись на общую поверхность в OpenCL
- Заблокируйте поверхность для монопольного доступа OpenCL.
- Запишите на эту поверхность через ядро C OpenCL. При работе с данными текстур необходимо использовать функции чтения или записи изображения и соответствующим образом передавать изображение.
- Разблокируйте поверхность, чтобы предоставить OpenGL доступ к ней на чтение или запись.
Шаги 1, 2 и 3 должны следовать в указанном порядке.
Цикл
Эта статья посвящена общему доступу к ресурсам между ЦП и ГП. Цикл рендеринга использует простой проход через программируемый шейдер вертексов и пикселей для создания текстурной карты для двух треугольников, образующих вместе четырехугольник. Этот четырехугольник не занимает полный экран, чтобы был виден цвет фона.
Завершение работы
- Очистка состояния OpenCL
- Очистка состояния OpenGL
Подробные сведения об общем доступе к поверхностям OpenGL и OpenCL
В этом разделе приводятся подробные сведения об этапах, описанных в предыдущем разделе.
Инициализация
- OpenCL:
- Выдайте запрос, чтобы определить, поддерживаются ли расширения; завершение и выход, если не поддерживаются.
Не все реализации OpenCL поддерживают общий доступ к поверхностям OpenCL и OpenGL, поэтому сначала нужно определить, есть ли вообще в системе нужное расширение. Мы последовательно перебираем платформы, чтобы найти строку расширения для платформы, поддерживающей общий доступ к поверхностям. Внимательное изучение спецификации показывает, что это расширение платформы, а не устройства. Затем мы создаем контекст, который нужно будет опросить, чтобы определить, какие из наших устройств в контексте поддерживают общий доступ к контексту OpenGL.
Этот пример поддерживается только на ГП Intel, но можно без особых усилий реализовать поддержку и других ГП. Нужное нам расширение - cl _ khr _ gl _ sharing . Вот соответствующий фрагмент кода. char extension_string; memset(extension_string, "
- Выдайте запрос, чтобы определить, поддерживаются ли расширения; завершение и выход, если не поддерживаются.